前回は、全体の構成と「楽天レシピ系APIから情報を取得し、Elasticsearchに情報を投入する。」処理について書いたので、今回は「ユーザーからの画像を解析し、Elasticsearchからレシピを検索する。」について書きたいと思います。
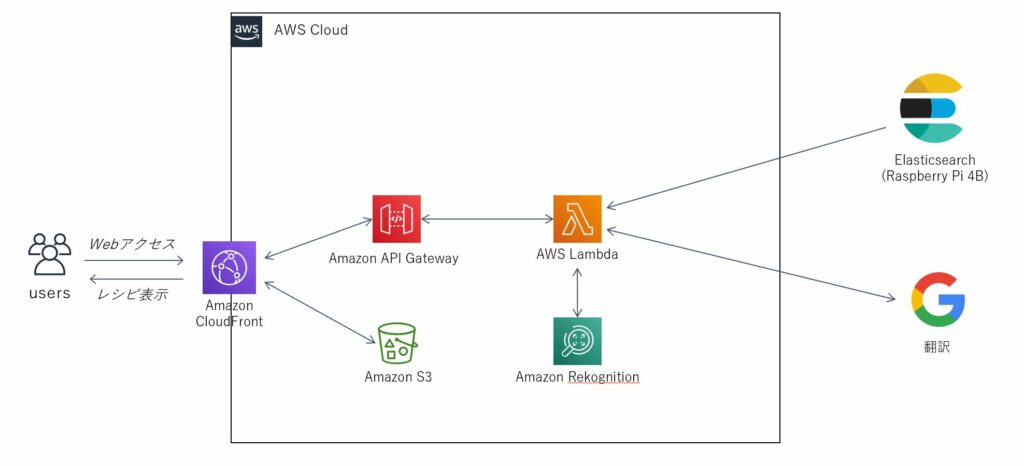
1、ブラウザにページが表示されるまでの処理
今回、Webページはvuetifyを使用して作成しました。作成したHTMLファイルはS3バケットにアップロードし、パブリックアクセスを有効にします。
ユーザーはS3バケットのファイルに直接アクセスするのではなく、CloudFrontを経由してアクセスする構成とします。このように設定すると、CloudFrontでキャッシュが効き、S3バケットからの転送量を減らすことが出来ます。
また、CloudFrontに証明書を設定することで、証明書管理も楽になります。
2、画像を送信し、レシピが表示されるまでの処理
Webページで画像を取得すると、CloudFront→APIgatewayを経由してLambdaが起動します。
Lambda内ではブラウザから送信された画像情報を抽出し、rekognitionへデータを投入します。rekognitionの解析結果は配列として返されます。
rekognitionの解析結果は英語で記述されています。しかしながら、Elasticsearch内のレシピデータは日本語で記述されているため、そのままだと解析できません。
rekognitionの解析結果は一旦Google 翻訳APIに投入し、日本語に翻訳します。翻訳後にElasticsearchで検索を行います。
Elasticsearchの解析結果はJSON形式に成形し、ブラウザへ送信します。
import base64
import boto3
import json
from googletrans import Translator
from elasticsearch import Elasticsearch
from elasticsearch_dsl import MultiSearch, Search
import collections as cl
translator = Translator()
es = Elasticsearch(
['ドメイン名'],
http_auth=('ユーザー名', 'パスワード'),
scheme="https",
port=443,
)
#boto3のclientを作成し、rekognitionとリージョンを指定
client = boto3.client('rekognition','ap-northeast-1')
def lambda_handler(event, context):
# TODO implement
#print(event)
images = event['body'].split(',',2)
img_binary = base64.b64decode(images[1])
response = client.detect_labels(
Image={'Bytes': img_binary}
)
word_list = []
for value in response['Labels']:
word_list.append(value['Name'])
#print(value['Name'])
Search_word= ""
translations = translator.translate(word_list, dest='ja')
for translation in translations:
Search_word = Search_word + " " + translation.text
print(Search_word)
s = Search().using(es).query("multi_match", query=Search_word, fields=['title', 'materials','description'])
response = s.execute()
Count = 0
output = cl.OrderedDict()
for hit in s:
data = cl.OrderedDict()
data["detail_url"] = hit.detail_url
data["image_url"] = hit.image_url
data["title"] = hit.title
data["description"] = hit.description
output[Count] = data
Count = Count + 1
return {
'statusCode' : 200,
'headers' : {'content-type' : 'application/json'},
'body' : json.dumps(output)
}